
Wir haben nun schon einige wichtige Schritte des Wegs zum papierlosen privaten Büro hinter uns. Ich habe in den vorherigen Kapiteln bereits das Dateiformat PDF verwendet - zum Teil auch PDF/A - ohne näher darauf einzugehen, weshalb überhaupt das Dateiformat PDF/A.
Anforderungen
Die Anforderungen sind leicht zusammengetragen. Was soll das Dateiformat können, mit dem wir unsere Dokumente in Zukunft speichern:
-
Langzeit verfügbar: Ein großes Risiko beim digitalen Speichern ist, dass die Daten in einigen Jahren nicht mehr gelesen werden können. Eine Word-Datei, die mit Word 95 erstellt wurde, kann zwar vielleicht noch geöffnet werden ... Aber sieht diese genauso aus wie zum Zeitpunkt der Erstellung? Hierzu ist es notwendig, dass es sich um einen offenen normierten Standard handelt, der ausreichen dokumentiert ist.
-
Unabhängigkeit: Das Dateiformat sollte unabhängig vom Betriebssystem oder einzelnen Applikationen und Firmen sein.
-
Weite Verbreitung: Das Dateiformat sollte weit verbreitet sein. Ich möchte eine Datei nicht jedes Mal konvertieren müssen, wenn ich diese zu meinem Steuerberater, meinem Arbeitgeber oder meiner Hausverwaltung schicke. Zudem erhöht eine hohe Verbreitung die Wahrscheinlichkeit, dass das Format auch noch in mehren Jahren lesbar sein wird.
-
Mehrseitige Dokumente: Es soll möglich sein, dass wir mehrseitige Dokumente in einer einzigen Datei speichern.
-
Textebene: Es soll nicht nur die Rastergrafik, die unser Scanner erstellt, in der Datei hinterlegt sein, sondern auch eine Textebene (oder Textelemente) (Stichwort: OCR).
-
Keine externen Abhängigkeiten: Öffnet man mit LibreOffice eine Word-Datei unter Linux, funktioniert dies mittlerweile relativ gut. Kritisch wird es aber spätestens, wenn eine Schriftart verwendet wird, die unter Linux (oder auch auf einem anderen Windows Rechner) nicht verfügbar ist. Das Dateiformat sollte also keine externen Abhängigkeiten z. B. zu Schriftarten haben.
Die Formate
Infrage kommen somit eigentlich nur zwei Dokumentenformate. PDF/A und DjVu.
DjVu
DjVu ist ein von Anfang an offenes Dokumentenformat zur Dokumentenarchivierung. DjVu existiert seit 1998 und wurde von AT&T entwickelt.
DjVu ermöglicht kleinere Dateigrößen als PDF. Allerdings fristet DjVu eher ein Nischendasein. Während zwar viele Dokumentenbetrachter unter Linux DjVu darstellen können, ist dies unter Windows die Ausnahme. Auch Tools (wie OCRmyPDF) sind eher spärlich gesät.
Da ein entscheidender Punkt jedoch auch der Austausch von Dokumenten mit anderen Personen ist, ist DjVu ungeeignet. Selbst wenn es technisch unproblematisch wäre, würde eine unbekannte Dateiendung mindestens Fragezeichen beim Gegenüber hervorrufen. Zudem führt eine geringe Verbreitung unweigerlich dazu, dass eine Technologie früher obsolet wird.
PDF/A
PDF steht für Portable Document Format und wurde 1993 von Adobe als proprietäres Format veröffentlicht. PDF/A ist eine spezielle Variante des PDFs zur Langzeitarchivierung und wurde 2005 in der Version PDF/A-1 als ISO-Norm ISO 19005-1 standardisiert. Somit ist PDF/A ein offener Standard und wird durch die PDF Association gepflegt und weiterentwickelt. 2012 wurde der aktuelle PDF/A-3 Standard in der ISO 19005-3 veröffentlicht. Wobei PDF/A-3 nicht PDF/A-1 ablöst, sondern nur erweitert. PDF/A-1 ist also nicht obsolet.
PDF/A schreibt einzelne Elemente vor und verbietet andere Elemente. So ist beispielsweise Javascript, wie es häufig in PDFs mit Formularen verwendet wird, nicht zugelassen. Auch transparente Elemente oder eine dokumenteninterne Verschlüsselung sind in PDF/A-Dateien nicht erlaubt. Dies alles soll sicherstellen, dass die Dateien auch noch nach vielen Jahren lesbar sind.
Alle PDF-Standards haben immer die Dateiendung .pdf. Es ist also auf den ersten Blick nicht zu erkennen, ob es sich um ein "normales" PDF oder ein PDF/A handelt.
PDF/A-Dateien erfüllen alle genannten Anforderungen:
- PDF/A ist explizit zur Langzeitarchivierung gedacht.
- PDFs können unter allen Betriebssystemen mit vielen unterschiedlichen proprietären und freien Viewern betrachtet und erstellt werden. PDF wird nicht mehr alleine von Adobe entwickelt, sondern von der 'PDF Association' und ist ISO-standardisiert und somit ein offner Standard.
- PDF ist der Standard zum Dokumentenaustausch, ist in vielen Webbrowsern integriert und ist jedem Laien ein Begriff.
- PDF/A-Dateien können mehrseitig sein und eine Textebene haben.
- PDF/A (nicht PDF im Allgemeinen) stellt sicher, dass es keine externen Abhängigkeiten oder Funktionen gibt, die in wenigen Jahren nicht mehr vorhanden oder kompatibel sind.
Randnotiz: Auch PDFs sollte man aus unbekannten Quellen nicht öffnen. PDFs können diverse Elemente enthalten und ggf. Schadcode transportieren.
Randnotiz 2: In PDFs ist der Text keine eigene Ebene, sondern wird in unsichtbaren Text-Elementen untergebracht.
Mehr Details zum Thema Langzeitarchivierung kann man hier finden: Link. Unter anderem sind dort auch mehrere Studien zu Dateiformaten und deren Verbreitung und Langlebigkeit enthalten.
Fazit
PDF/A ist für die genannten Zwecke das ideale Dateiformat. Die Wahrscheinlichkeit, dass die Dateien noch in 10 oder 20 Jahren gelesen werden können, ist durch die Standardisierung und die hohe Verbreitung am größten. Sollte PDF/A sich irgendwann dem Ende seines Lebenszyklus näheren, kann man zudem ziemlich sicher sein, dass es Möglichkeiten zur Konvertierung geben wird.
Auch die "alten" PDF/A Versionen haben heute noch Gültigkeit. Alle neuen PDF/A-Versionen sind nur Erweiterungen. Auch in Zukunft ist also nicht zu erwarten, dass sich hier schnell etwas ändert.
Alle Empfehlungen, die ich finden konnte, sprechen sich für PDF/A zur Langzeitarchivierung aus.
PDF/A im Workflow
Wie wird PDF/A nun beim bereits beschriebenen Schritt 1 und Schritt 2 verwendet?
Das verwendete SimpleScan / Document Scanner speichert die Dateien als einfaches PDF. Aktuell nach dem Standard "PDF v. 1.3". Dies lässt sich einfach herausfinden, wenn man im Dokumentenbetrachter Okular auf "File --> Properties" geht.
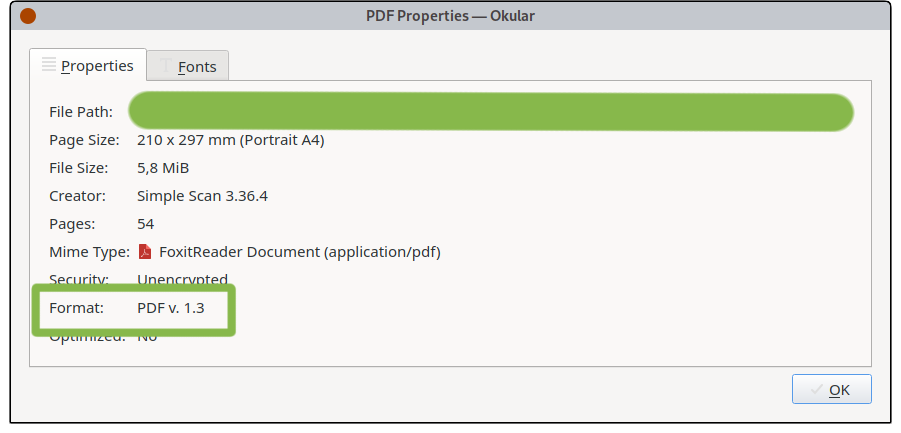
Wir wollen aber ja nun ein PDF/A haben. Netterweise übernimmt dies OCRmyPDF für uns. Per Default speichert OCRmyPDF die Ergebnisdatei als PDF/A-2B. Es muss also nichts weiter unternommen werden, sondern wir haben bereits ein PDF/A erzeugt.
Aber schaut man die Dateiproperties nun mit Okular an, wird "PDF v. 1.6" erkannt. Also eventuell doch kein valides PDF/A Dokument?
Verifikation mittels VeraPDF
Es muss also noch eine Möglichkeit her zu verifizieren, dass wir ein valides PDF/A haben. Dieses Thema ist technisch gar nicht so einfach, da der PDF/A-Standard sehr komplex ist und nicht alle Implementierungen vollständig sind. Die Wahrscheinlichkeit, dass beim Generieren etwas schief gelaufen ist, ist also gar nicht so gering.
Hier kommt VeraPDF ins Spiel. VeraPDF ist eine Open Source (GPLv3+) Software, welche von der Europäischen Kommission finanziert und durch das veraPDF Konsortium entwickelt wurde. Mittels der Software können PDF/A-Dokumente validiert werden, ob diese wirklich allen Anforderungen der ISO 19005 entsprechen. Die Version 1.0 von VeraPDF ist 2017 erschienen und wird auf github gepflegt.
VeraPDF ist in Java entwickelt und ist für Windows, Linux und Mac verfügbar. Der Download kann direkt bei VeraPDF erfolgen: Link oder im Falle von Manjaro ist VeraPDF auch über das AUR verfügbar und kann dort einfach installiert werden.
VeraPDF besteht aus zwei Teilen. Es gibt eine GUI-Applikation und eine CLI-Applikation.
Machen wir zunächst einen Test über die GUI. Mittels
verapdf-gui
oder auch über das Startmenü kann die GUI gestartet werden. In der GUI selektiert man nun nur das jeweilige PDF und geht auf 'Execute'. Das Ergebnis ist sofort zu sehen.
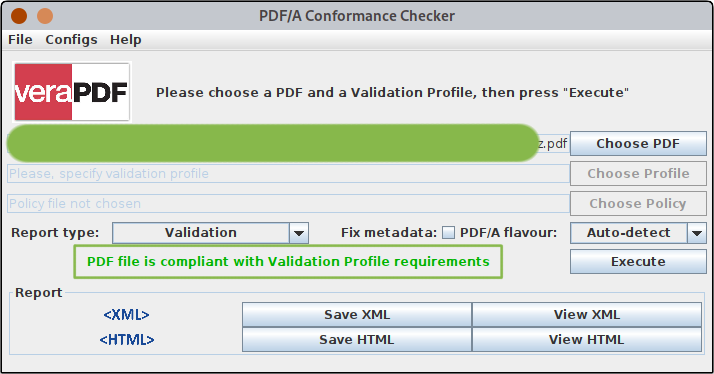
Jedes einzelne PDF, das durch OCRmyPDF erzeugt wurde nun händisch über die GUI zu prüfen, passt gar nicht gut in den Workflow. Zum Glück gibt es auch das CLI:
verapdf MeineDatei.pdf
Als Ergebnis bekommt man ein ziemlich ausführliches XML angezeigt. Die entscheidende Information für uns:
<validationReports compliant="1" nonCompliant="0" failedJobs="0">1</validationReports>
Das PDF ist also compliant nach einem PDF/A-Standard. Man kann natürlich auch auf eine spezielle PDF/A-Version prüfen. Dies ist mir jedoch nicht wichtig.
Nun ist das Ganze aber noch immer ein wenig unhandlich. So wie ich mit einem einzelnen Befehl alle PDF-Dateien im Arbeitsverzeichnis mittels OCRmyPDF mit einer Textebene versehen konnte und zum PDF/A umwandeln konnte, möchte ich nun auch alle Dateien auf einen Schlag überprüfen. Zudem möchte ich eine Liste mit allen nonCompliant Dateien haben.
Hierfür habe ich mir ein kleines Python Script "verify.py" geschrieben, welches ihr unter https://github.com/rsmuc/paperless herunterladen könnt.
Das Ergebnis sieht nun so aus:
python3 verify.py
Verifiy:./bak/kaputt.pdf
DOCUMENT BROKEN
Verifiy:./bak/ok.pdf
OK
################################
################################
################################
COMPLIANT DOCUMENTS: 1
NONCOMPLIANT DOCUMENTS: 1
NON COMPLIANT FILES:
./bak/kaputt.pdf
So können wir nun also auf einen Blick sehen, dass bei einem Dokument wohl etwas schiefgelaufen ist und wir dieses noch einmal näher betrachten müssen. (Im oben genannten Beispiel: Es ist ein PDF und kein PDF/A.)
Somit haben wir eine weitere wichtige Grundlage geschaffen.
Feedback
Kommentare und Feedback gerne in den Github issues oder über Mastodon @muc.mastodon.bayern mit dem Hashtag #PDFA

Comments
May 26, 2023 09:18
The article’s inclusion of best practices and rankdle optimization tips for Vue developers in the trackside context shows the author’s expertise in the field.